There is a common expression in technology domains being “garbage in, garbage out”. The expression was popular in the early days of computing and is even more relevant today as we utilize innovative technologies such as machine learning and artificial intelligence, which depend on combinations of large datasets from different data sources. It translates to if your input data is flawed, or even nonsense, then the output will be also.
In our everyday lives we are surrounded by labels. They are attached to cloth, buildings, food, books in libraries, our personal information and much more. Labels serve as a way of identification, as warnings, and simply for informational purposes.
A comprehensive and consistent approach to data labeling is one part of the process to ensure that “right” data is “going in” for the “right” data “to go out” to generate trusted results.
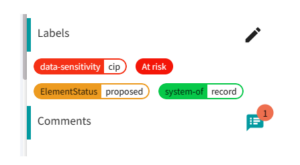 Data labeling provides users, teams, and the organization with additional context such that the data can be better understood, assessed and even how the data is to be used, shared, or restricted.
Data labeling provides users, teams, and the organization with additional context such that the data can be better understood, assessed and even how the data is to be used, shared, or restricted.
Data Labels can be applied to:
- Business Processes – By labeling data for different business process uses such as for regulatory, critical infrastructure protection (CIP), personally identifiable information (PII) and much more, the data is categorized for use.
- Data Governance – Data associated with a specific business domain can be labeled, and the appropriate data stewards, data owners, and even governance processes such as approval status, system of record or source of truth.
- Data Accuracy – The approach used to label data directly impacts the accuracy of results, by communicating the correct synaptic context of data for users of data, for integration with different technology platforms, and even for automated processing.
Data labeling helps to streamline data processing and can be insightful in reducing data duplication. It can also help to enable advanced analytics, such as machine learning and artificial intelligence, by providing a commonly understood and consistent view of the data, leading to better results.
 Getting Started with Data Labels
Getting Started with Data Labels
Data Labels in Affirma are easy to create and apply to a wide range of Affirma Capabilities such as:
- Data Catalog
- Data Dictionary
- Enterprise Semantic Model
- Mapping and Transformation
- Build Automation
- AND MORE
Through Data Labels data context and information is communicated across the organization from business users to IT developers, from data scientists to data analyst, from python developers to analytic report designers.
SOMETHING TO CONSIDER
- Start with a small set of labels – make sure to start small and grow, focus on identifying a finite set of labels.
- Start with the burning issues – if there are specific issues in the organization around data definitions start with those. Perhaps there is a new regulatory requirement or system upgrade project. Focus on labels that can help make life easier for people in getting their job done.
- Make it part of your process – the organization has dozens if not hundreds of projects going on every year that involve data. Define the process and how labels will be used and expand your data labels over time.
It is important to understand that data is a valuable asset within an organization and should be treated as such. One way to make it more valuable is to label it, just like we label items all around us in our everyday lives. Where would you be if public transportation was not labeled?
Future of Data Labels in Affirma
Under the “covers” Affirma associates all the various aspects of metadata management, including Data Labels, into a connected ontology in a knowledge graph. The knowledge graph approach is an underpinning differentiator of Affirma which will allow us to integrate machine learning (ML) and natural language processing (NLP) in the future, automating Data Label associations, driving active data management to keep pace with today’s data and governance demands.